













These guidelines initially describe the difference between reliability testing and defect testing. A short description of Software Reliability Engineering (SRE) is then provided, which is a method for achieving reliability testing. Finally, an example of the application of SRE to a system is provided.
There are two main goals in testing software. On the one hand, testing can be seen as a means of achieving reliability: here the objective is to probe the software for faults so that these can be removed and its reliability thus improved. Alternatively, testing can be seen as a means of gaining confidence that the software is sufficiently reliable for its intended purpose: here the objective is reliability evaluation.
First consider a developer who tests to find and correct faults and improve the delivered software. A systematic testing method includes a criterion for selecting test cases and a criterion for deciding when to stop testing. Most common approaches to systematic testing are directed at finding as many faults as possible, by either sampling all situations likely to produce failures (e.g. methods informed by code coverage or specification coverage criteria), or concentrating on situations that are considered most likely to do so (e.g. stress testing or boundary testing methods). The choice among such testing methods will depend on hypotheses about the likely types and distributions of faults at the point in the software development process when testing is applied. These approaches, collectively, are known as “defect testing”.
A completely different approach is “reliability testing”, where the software is subjected to the same statistical distribution of inputs that is expected in operation. Instead of actively looking for failures, the tester in this case waits for failures to surface spontaneously, so to speak.
In comparing the relative advantages of reliability testing and defect testing, important points are:
- Defect testing may be more effective at finding faults (provided the intuitions that drive it are realistic), but if it uncovers many failures that occur with negligible rates during actual operation, it will waste test and repair efforts without appreciably improving the software. Reliability testing, on the other hand, will naturally tend to uncover earlier those failures that are most likely in actual operation, thus directing efforts at fixing the most important faults.
- The fault-finding effectiveness of a defect testing method hinges on whether the tester’s assumptions about faults represent reality; for reliability testing to deliver on its promise of better use of resources, it is necessary for the testing profile to be truly representative of operational use.
- Reliability testing is attractive because it offers a basis for reliability assessment, so that the developer can have not only the assurance of having tried to improve the software, but also an estimate of the reliability actually achieved.
Software reliability is defined as the probability of failure-free software operation for a specified period of time in a specified environment. Software reliability is an attribute and key factor in software quality. Software Reliability Engineering (SRE) is one method for achieving software reliability.
The essential components of SRE are categorised as follows:
- Establish reliability goals
- Develop operational profile
- Plan and execute tests
- Use test results to drive decisions
These components are sequential. Although these SRE elements are addressed in isolation the reader should note that in reality they are integrated within the software development process. Reliability goals are part of the requirement definition process. Development of the operational profile occurs in parallel with software design and coding. Testing for reliability is a testing approach which is included in the overall test plan.
Reliability goals describe the customer’s expectation of satisfactory performance of the software in terms that are meaningful to the customer. This description may be significantly different from the theoretical definition of reliability, but the customer has no need for the theoretical definition. The customer must tell you the circumstances under which they will ‘trust’ the system you build. For example, someone who purchases a fax machine wants assurance that 99 out of every 100 faxes received will print properly. The fact that the machine must run for 25 hours without failure in order to demonstrate the specified degree of reliability is irrelevant to the customer. In order to test for reliability we often need to translate expressions that are meaningful to the customer into equivalent time units, such as execution time, but the goal remains as the customer perceives it.
What is important is that these customer needs, or expectations, are described in a quantifiable manner using the customer’s terminology. They do not have to be statements of probability in order to be useful for determining product reliability. Some examples of quantified reliability goals are:
· The system will be considered sufficiently reliable if 10 (or less) errors result from 10,000 transactions.
· The customer can tolerate no more than one class 2 operational failure per release and no class 1 failures per release for a software maintenance effort.
All participants in the development (or maintenance) process need to be aware of these reliability goals and their prioritisation by the customer. If possible this awareness should come from direct contact with the customer during the requirements gathering phase. This helps to cement the team around common goals. Ideally, reliability goals should be determined up front before design begins; however defining them at any point in the life cycle is better than not having them.
The operational profile characterises system usage. Use of this profile is what distinguishes SRE from traditional software development. In order to make a good reliability prediction we must be able to test the product as if it were in the field. Consequently we must define a profile that mirrors field use and then use it to drive testing, in contrast to defect testing. The operational profile differs from a traditional functional description in that the elements in the profile are quantified by assignment of a probability of occurrence, and in some cases a criticality factor. Development and test resources are allocated to functions based on these probabilities.
Use of the operational profile as a guide for system testing ensures that if testing is terminated, and the software is shipped because of imperative schedule constraints, the most-used (or most critical) operations will have received the most testing and the reliability will be maximised for the given conditions. It facilitates finding earliest the faults that have the biggest impact on reliability.
The cost of developing an operational profile varies but is non-linear with respect to product size. Even simple and approximate operational profiles have been shown to be beneficial. A single product may entail developing several operational profiles depending on the varying modes of operation it contains and the criticality of some operations. Critical operations are designated for increased or accelerated testing.
Under SRE the operational profile drives test planning for reliability. Probability and critical factors are used to allocate test cases to ensure that the testing exercises the most important or most frequently used functions first and in proportion to their significance to the system.
Reliability testing is coupled with the removal of faults and is typically implemented when the software is fully developed and in the system test phase. Failures identified in testing are referred to the developers for repair. A new version of the software is built and another test iteration occurs. Failure intensity (for instance, failures per transaction or time unit) is tracked in order to guide the test process, and to determine feasibility of release of the software.
The testing procedure executes the test cases in random order - but because of the allocation of test cases based on usage probability, test cases associated with events of greatest importance to the customer are likely to occur more often within the random selection.
A normalised reliability growth curve can be used to predict when the software will attain the desired reliability level. It can be used to determine when to stop testing. It can also be used to demonstrate the impact on reliability of a decision to deliver the software on an arbitrary (or early) date. Figure 1 illustrates a typical reliability curve. It plots failure intensity over the test interval.
The failure intensity figures are obtained from tracking failures during testing. Test time represents iterative tests (with test cases selected randomly based on the operational profile). It is assumed that following each test iteration, identified faults are fixed and a new version of the software is used for the next test iteration. Failure intensity drops and the curve approaches the pre-defined reliability goal.
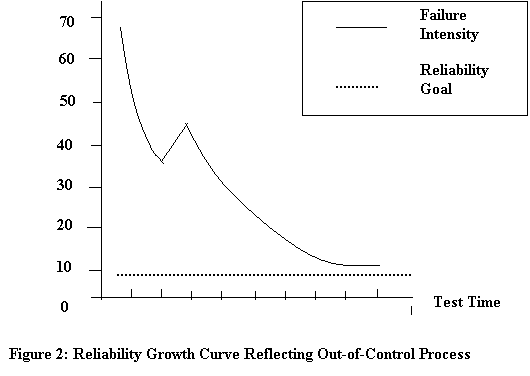
Figure 2 illustrates what may happen when the process for fixing detected errors is not under control, or a major shift in design has occurred as a result of failures detected.
Failure intensity drops, spikes, and then makes a gradual decline. Any predictions made prior to the 3rd test iteration would be grossly inaccurate because the spike could not be foreseen. The changes actually introduced new errors while attempting to fix the known errors. This graph identifies two potential problems. The process for fixing errors may be inadequate and there may be weak areas in the development process (analysis and design) itself which are the root cause of this erratic reliability profile. This type of graph is more likely to occur in projects where the developer prefers to let the testing find the errors rather than design for defect prevention up front.
![]()
This guidelines section is based on an article by Ellen Walker, titled ‘Applying Software Reliability Engineering (SRE) to Build Reliable Software’, published by the Reliability Analysis Center and a paper by P.G. Frankl, R.G. Hamlet, B. Littlewood and L. Strigini, titled ‘Evaluating Testing Methods by Delivered Reliability’, published in IEEE Transactions on Software Engineering, Vol. 24, No. 8, August 1998.
|